

(上)【一文掌握AI绘图】Stable Diffusion 绘图喂饭教程

查阅、整理和输出教程属实不易,觉得这篇教程对你有所帮助的话,不妨点个赞和在看。
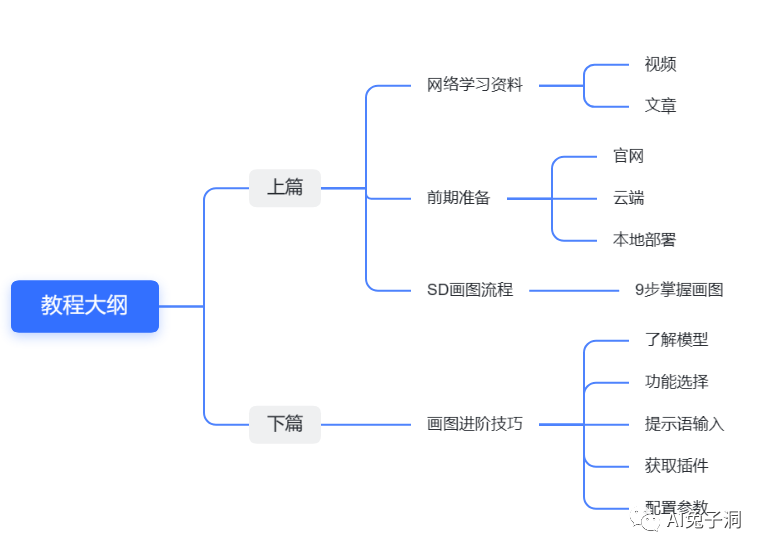
1、非常详细的讲解和描述,包括你想了解的所有方面,建议通读一遍对SD的内容有个轮廓。
https://www.uisdc.com/stable-diffusion-2

2、喂饭级别的教程,从环境安装、技术原理、再到功能详情的讲解,推荐看。
https://www.bilibili.com/video/BV1k54y1T7Lf/?spm_id_from=333.788&vd_source=b5296bfab5d03086dcfe9f754eb1a553

3、作者深入浅出的将自己的经验分享了出来,包括如何描述一张图片,如何正确输入提示语,以及作者对AI行业的未来发展的一些看法。
https://github.com/gdin2015cs21/understand-prompt

4、可以说是很详细的介绍了,小姐姐教你用AI画图,很系统教学的一个视频系列,扫盲必看:
https://www.bilibili.com/video/BV1eL411176f/?share_source=copy_web&vd_source=eb46e9ffc765ae89070146d6c4acb4e7

前期的环境准备有三种方式,云端执行、本地部署和官方地址,云端执行可参考我往期的教程,推荐入门玩家使用,可尝试不同的模型和风格,真要实际应用于生产力或生产高质量的内容,还是需要在本地部署,不然云端执行不稳定且性能差劲。官方地址可以直接在线打开使用,只是功能比较简陋,推荐小白玩家尝鲜玩耍。
(1)官方地址:(小白)
只有简单的输入提示词和生成图片的功能,微调的参数不多,但可以体验AI画图的魅力:
https://beta.dreamstudio.ai/generate

(2)云端执行:(入门)硬件条件不行的伙伴建议使用
参考往期教程 :
https://ki6j1b0d92h.feishu.cn/wiki/wikcnAAaqXkqK8pMDjv8EENrRB0

(3)本地部署:(进阶)推荐使用💯
1、大家有本地部署的需要话,可以查看这个B站活佛秋叶大佬视频,有一键部署的方式,很适合小白使用:
https://www.bilibili.com/video/BV17d4y1C73R/?spm_id_from=333.788.video.desc.click

https://www.bilibili.com/video/BV1ne4y1V7QU/?share_source=copy_web&vd_source=eb46e9ffc765ae89070146d6c4acb4e7

我用夸克网盘分享了「sd-webui-aki」,点击链接即可保存。打开「夸克APP」,无需下载在线播放视频,畅享原画5倍速,支持电视投屏。
链接:https://pan.quark.cn/s/eccf8807fa3e

2、有代码背景的大佬,可以直接参照官方文档进行部署,不懂代码的就不建议搞了,麻烦:
https://github.com/AUTOMATIC1111/stable-diffusion-webui/wiki
三、SD画图流程

-
选择合适的模型
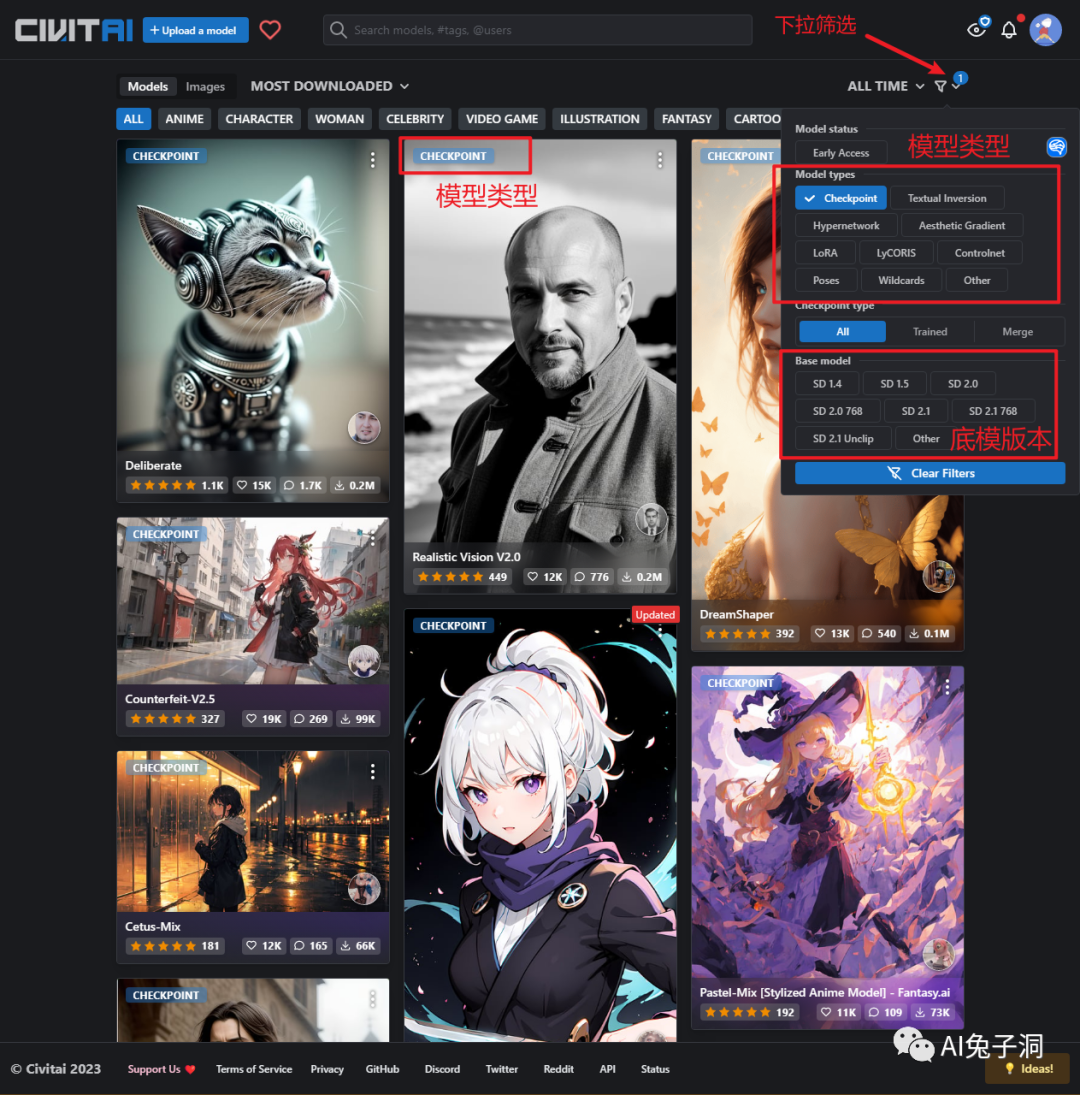
要想通过SD画图得到一张精美的图片,必须先找到合适的模型,因为图片等风格和特征是基于模型生成的,不同的模型适用于不同的场景和风格中。
因此第一步我们需要确定图片的大致风格和类型,接着到著名的C站(https://civitai.com/)中寻找有无符合要求的模型,找到目标模型点击进去,我们可以看到模型的一些详细介绍,重点需要关注的就是该模型的类型和底模版本。
-
- 模型类型的配置方式不同,所以需要提前了解;
-
底模版本决定了底层的模型内容和生图速度(tip:2.0+的版本不能瑟瑟)


确定合适的模型后,我们需要吧模型导入到SD中,这里分别介绍云端和本地两种导入的方式:
(1)云端导入(点击展开)



(2)本地导入(点击展开)
本地导入需要先下载模型(下载开始后可以先关闭代理,可以节省梯子购买的流量),下载完毕后根据不同的模型类型放入对应的本地文件夹中,回到SD页面点击刷新即可看见导入的模型。(不同模型类型的文件夹地址见下文)


-
选择功能类型
完成模型的准备后,我们回到SD的页面中,默认就是选中文生图的选项卡,在这个选项卡中我们可以根据输入的提示词内容生成对应的图片内容:

-
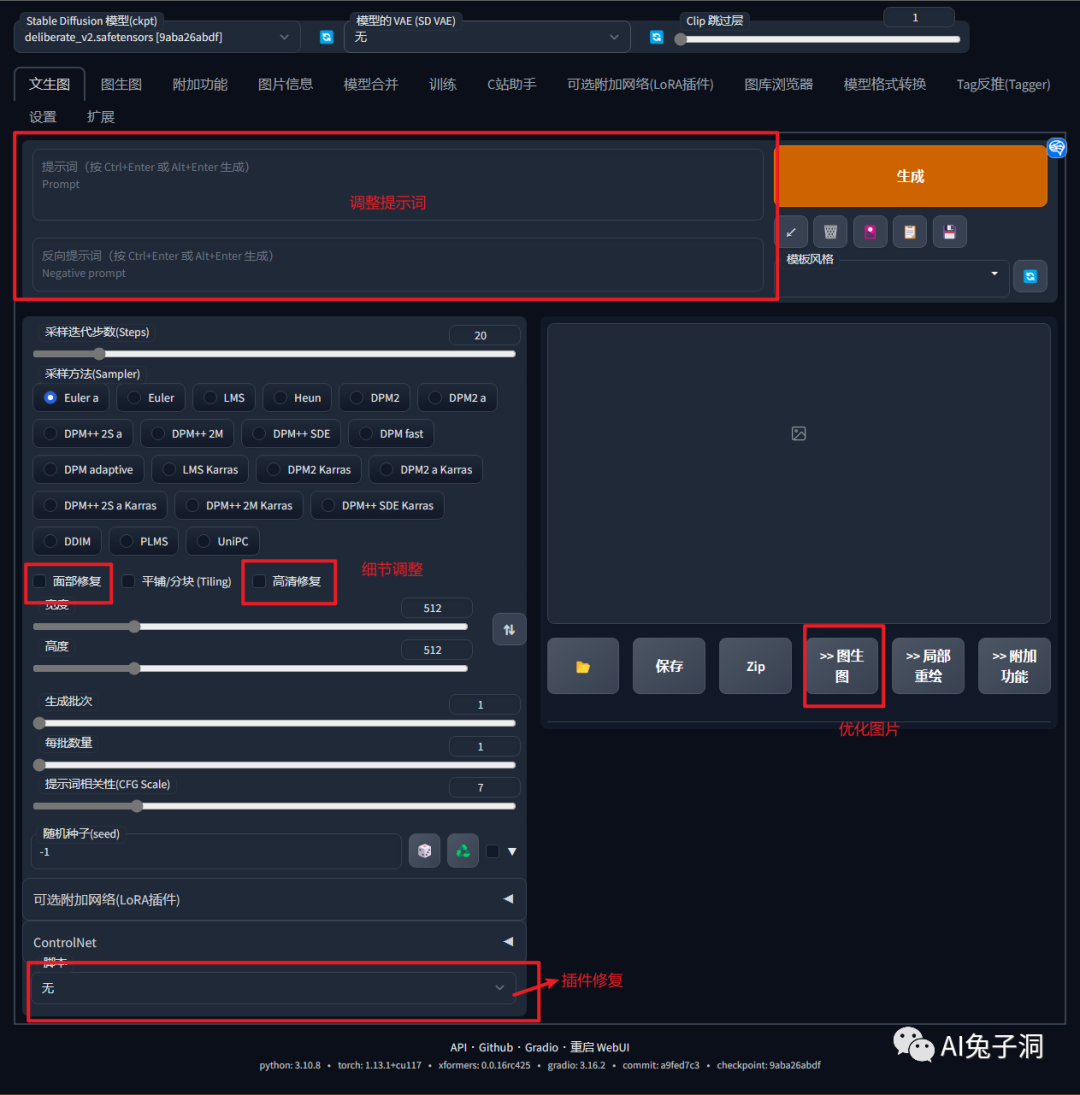
输入提示词
提示词分为两种,分别是正向提示词和反向提示词,正向提示词用来输入目标图片的关键特征词汇,反向提示词用来排除图片中不需要的内容。一张精美的图片少不了反向提示词,需要通过大量的词汇来屏蔽图片中的异常内容,换句话说图片中出现你不想要的内容,你就把该改词汇添加到反向提示词中重新生成。
其次,若有些提示词是常用的,可以将提示词保存为模板,这样就可以通过右侧的下拉选项中快速选择和使用了,常用于保存和选择一些万能通用的提示词。
提示词的模板和填写规范可以查看【下篇教程】。

-
参数调整
在C站中找到模型的效果图信息,参照着作者给出的参数信息,将参数值填入SD的参数配置区中,只有每个参数都还原才能生成与作者相同的图片效果,如果发现还是不一致,那可能就是硬件上的不同,导致随机种子的值有所差异,所以不能做到一比一的还原。


快速复用所有参数技巧:

-
选择合适的插件
插件能让SD的定制化能力更上一层楼,根据图片需求选择合适的插件,并完成插件的参数要求配置,这样就能在模型的基础上加上插件效果了,普通情况下可以不选择插件进行生图。
插件的获取和安装可见下文

-
生成图片
当一二三四五步都已完成,我们就可以生成图片了,图片输出的速度取决于运行的环境性能(显卡性能越高越快)、图片设置的宽高(宽高越大越慢)、生成的批次和每批数量(图片数量越多越慢)、是否勾选高清修复(勾选后速度慢)等因素。
图片生成的过程可以通过控制台查看进度详情,能看出每一步的执行需要的时间,图片异常也可以在控制台中查看报错信息,养成出现异常时从控制台中定位问题的习惯。


-
图片是否满意
可在右侧的图片输出区域查看输入的结果,点击图片可放大查看。

-
保存并下载图片
若图片生成效果满意,则可以点击图片下方的保存按钮,注意点击保存后需要点击下方的【download】才是进行本地下载,若想打包下载则直接点击【ZIP】按钮。

-
调整图片
若图片不满意,则一般通过以下几种方式来调整图片:
- 补充提示词:在正向提示词中补充细节描述,或加重和减轻某些词汇的权重;
- 补充反向提示词:在反向提示词中进一步补充图片中不好的效果词汇,不断减少负面效果,提高图片的品质;
- 面部修复:当不满意人像的面部效果时,则可以勾选这个选项尝试修复;
- 增强图片品质:当图片的效果不满意时,可以使用插件进行针对性的修复和重新生图,比如图片降噪、手部修复或分辨率增强等,都可以通过插件的方式来弥补,具体使用可查看【下篇教程】;
- 优化图片:在同时生成的多张图片中发现一张还不错的,想要进一步增强图片品质的话,可以尝试【图生图】的按钮,能尽可能保留一张图的要素并重新生成,可以一直生成下去,直到选中一张你喜欢的。

四、下篇预告

看到最后都是最棒的!!觉得这篇教程对你有所帮助的话,不妨点个赞和在看呗
建议点击下面的查看原文哦,阅读体验会更好,有什么问题可以公众号留言哦
关注AI兔子洞,给你带来最新的AI资讯、实用技巧、变现分享和工具教程!



